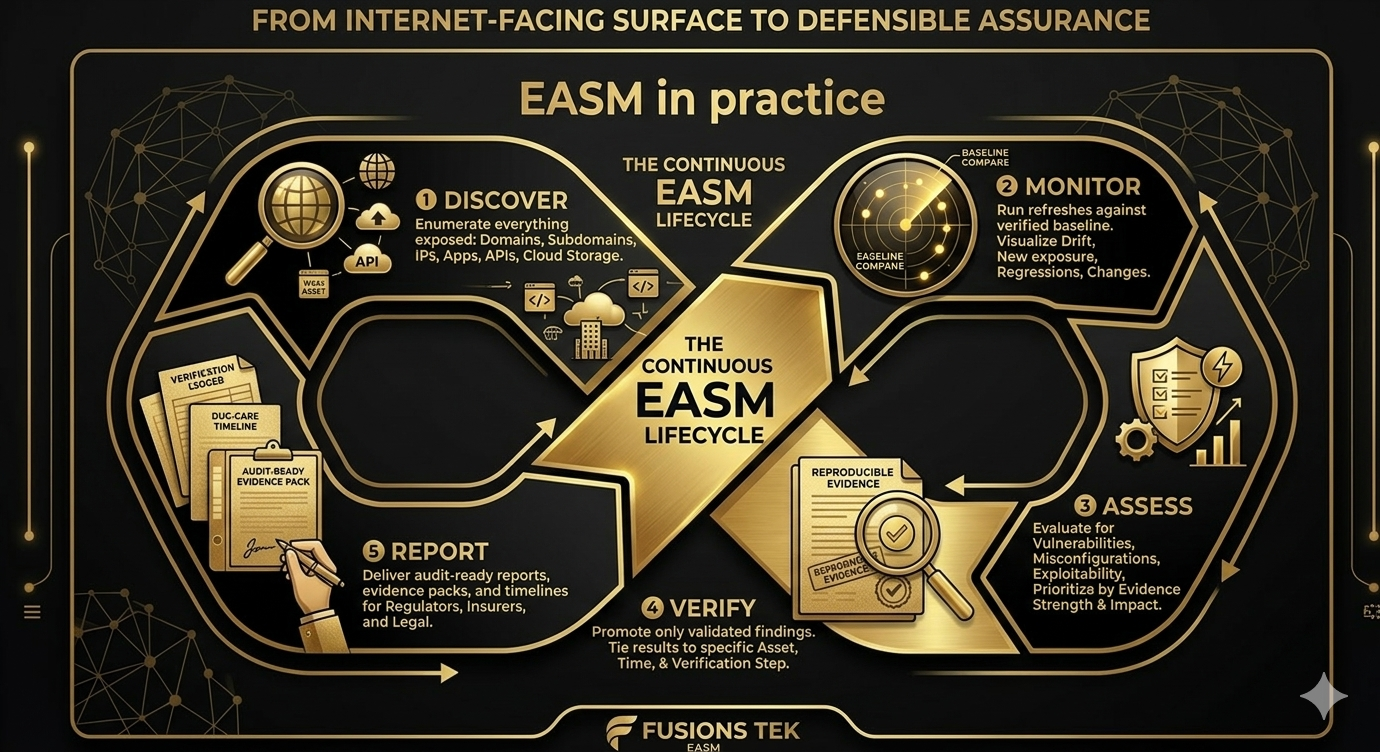
EASM — External Attack Surface Management — is the practice of discovering, validating, monitoring, and reporting on what your organisation exposes to the internet. Domains, subdomains, IPs, applications, APIs, cloud-attributed external assets, and perimeter-first third-party exposure correlation. The goal is risk reduction, not a one-off scan. When done right, EASM produces evidence designed to support auditor, insurer, legal, and leadership review. That only happens when validation is built in from the start.
This article explains what EASM actually is, how it differs from “scanning a list,” why validation is non-negotiable for assurance, and how due-care timelines turn EASM into an evidence-backed operating model.
What EASM is — and what it is not
EASM is the discipline of knowing and controlling your external attack surface: everything an attacker can see, enumerate, or reach from the public internet without being inside your network. That includes web applications, APIs, DNS records, TLS endpoints, cloud-attributed assets, CDN and edge configurations, third-party scripts and domains, and other internet-facing assets that could be targeted or abused.
EASM is not simply “running a vulnerability scanner.” Scanning is one activity within EASM — assessing discovered assets for known issues. But if your idea of EASM is “we have a list of domains and we scan them,” you are missing the core: discovery of what is actually there, plan- and scope-dependent refresh for change (drift), and evidence that what you report is validated and reproducible. Gartner and other analysts have consistently framed EASM as including discovery, inventory, prioritisation, and validation — not just point-in-time scanning (Gartner: Market Guide for External Attack Surface Management).
Discovery vs. scanning
Discovery means finding what is there: enumerating assets that attackers can reach, building a validated map of domains, subdomains, IPs, open ports, URLs, public endpoints, and technology stack. New subdomains appear. New APIs go live. Cloud-attributed assets are created. DNS and TLS change. If your EASM is only “scan the list we maintain,” you are relying on that list to be complete and up to date. In practice, lists go stale. Real EASM includes refresh against a baseline so that drift (what is new, changed, or gone) is visible.
Scanning is the step that assesses those discovered assets for vulnerabilities, externally observable misconfiguration signals, and exposure. It answers “is this asset weak or misconfigured?” Discovery answers “what assets do we have at all?” You need both. Without drift detection, you do not know when the surface has changed until an attacker or an auditor tells you.
Why verification matters
Findings without evidence are hard to use in audit, insurer, or post-incident reviews. A report that says “we think you might be exposed” is not the same as “we validated this endpoint at this time and here is the evidence.” Verification means that every promoted finding has the required evidence basis: the test was run, the result was recorded, and the evidence is tied to a specific asset, timestamp, and verification step. That is the difference between a noisy scan dump and an assurance-grade deliverable.
For compliance and risk transfer, the latter matters. Regulators and insurers increasingly expect evidence of security oversight — what was tested, when, and what was done about it. A structured due-care record gives reviewers the supporting record without implying guaranteed acceptance.
Due-care timeline
A due-care timeline is a structured record of observations, tests, and outcomes. Each finding ties back to a specific asset, a specific time, and a specific verification step. It does not only say “we found an issue.” It shows what was observed, when it was recorded, and how evidence changed over time. That is what turns EASM output into evidence designed to support audit or insurance review.
Due care means acting as a reasonable organisation would. Due-care timelines by latest scan, selected scan, or customer history show discovery, monitoring, assessment, and remediation with evidence. NIST SP 800-137 reinforces that security-relevant change has to be monitored and assessed over time, not captured once and treated as static truth (NIST SP 800-137).
Drift: when the surface changes and no one notices
If you run a scan once and never compare the next run to it, you do not know what changed. New exposure can appear — a new API, a forgotten dev subdomain, an externally observable cloud misconfiguration signal — and your report still reflects the old snapshot. That gap is silent drift. Attackers re-enumerate on a schedule. When something new appears, they may see it. When your tooling does not compare baseline to refresh, you do not. Drift detection turns EASM from a point-in-time report into a refresh-based operating model: establish a validated baseline, run refreshes, and classify the diff — new exposure, regression, removal, or noise — with evidence.
Evidence packs and review-ready deliverables
Security teams need to know which asset was tested, what was found, whether it was verified, and what should be fixed first. Auditors and insurers often ask to see that the issue was identified, reviewed, and remediated with evidence. That is why evidence packs matter: per-finding evidence (what was observed, how it was verified, when) and roll-up deliverables (due-care timeline, executive and technical reports) that support both operations and compliance. The same evidence that helps your team prioritise remediation is the same evidence you can point to when asked “how do you know?”
Policy and guardrails
EASM that runs without policy is a liability. Scope and consent boundaries ensure that testing stays within what you have authorised. High-risk actions should be defined before testing. The same policies that protect you operationally also support your narrative in an audit: we only tested what was in scope, in the way we said we would.
What teams should do next
- Treat EASM as discovery plus monitoring plus assessment plus verification. Do not settle for “we scan a list.” Ensure you compare current external evidence against a baseline.
- Insist on validation for every promoted finding. Separate validated findings from risk signals so teams can act without mixing confirmed issues with candidates that need review.
- Maintain due-care timelines. That is the evidence trail regulators and insurers may ask for when they review what was tested and when.
- Run refreshes against a baseline and classify drift. So you know what changed, what mattered, and whether your understanding of the surface is still current.
- Use evidence packs and review-ready reports. So the same deliverables that guide remediation also support compliance and risk transfer.
Summary
EASM done right is validation-first external assurance with evidence-grade visibility. It is not a one-off scan. It is discovery, plan- and scope-dependent refresh, validated assessment, and reporting designed to support auditor, insurer, legal, and leadership review. Validated findings, risk signals, due-care timelines, and evidence packs are what make it useful over time. That is what EASM is, and why verification matters.